前言
嗨,大家好,我是艦長。
歡迎來到系列文的第 7 篇。過去 6 篇,我鋪了很多梗,讓大家可以更多認識軟體圈與 Data 圈的差異,點出原來 Data 圈關心的產品就是 Data 本身。
這篇文我們繼續拉回一個不分軟體圈和 Data 圈的議題「為什麼我們需要可觀測性?」
軟體圈有監控,但還是會發生客戶比你更早打電話來反應:「欸,你們的服務,今天是不是怪怪的?」
而 Data 圈也同樣有做資料監控,可是 Data User 還是會跑來跟你說:「欸,這份報表的數字怪怪的喔!」
所以到底是為什麼,明明我們已經有做了許多努力,卻無法解決品質問題?

監控:見樹不見林的被動查核
前一篇文章中,我們有談到資料工程、資料監控。我覺得其實工程與監控這兩者都是基礎建設,也就是本來就該做的基本任務。
你本來就需要資料工程搭建資料管線去處理 Data,你的資料管線本來就該有基本的監控、告警與日誌功能。同樣你寫的軟體與線上服務,本來就該做好應有的 Error handling、Log 及監控告警等。
然而過去以來我們多半都是用一種「被動」的態度在處理「監控」。
- 因為有了 A,所以要加上 B 監控。
- 因為發生了 C,所以要加上 D 監控。
- 因為老闆說要 E,所以加上 F 監控。
也就是被動的檢核,「基於已知的問題,設定規則來檢查」。
並不是說監控(被動的檢核)就沒有用處,它當然很有用,它能幫我們發現與紀錄一些明確的問題,不然為什麼大家要在各種任務上,建立各種檢核表、SOP、檢核點。但它也有所侷限,容易形成一種局部、單點的查核。
可觀測性:提升系統資訊透明度的主動思維
而本系列文想要介紹的「資料可觀測性(Data Observability)」,則是受到近年(有人說是約 2010 年)開始在 IT 圈浮出水面之關鍵字「可觀測性(Observability)」的影響,約於 2019 年開始有人談論的題目。
有些文章會將可觀測性定義為,建立一套機制,讓我們可以透過主動觀測目標系統的「外部輸出」(例如:Logs, Metrics, Traces),以此有效的推斷、理解該系統的「內部狀態」,並且除錯那些「未知的問題」。
(謎之音:怎麼聽起來有點玄?)
我覺得這個定義點出「可觀測性(Observability)」最主要的重點是,讓我們建立一種「主動觀測」的思維。而這與 DevOps 提倡的提升「資訊透明度」是相符合的。
也就是過去我們也有做監控、有收集 Log、收集 Metrics,但是我們並沒有主動的去運用這些「監控資料」。
而自從進入可觀測性 1.0 的時代之後,我們開始對「監控」加入了主動性,即是我們不只做過去的那些收集 Logs、收集 Metrics、設立告警 Rules 的基本建設。我們還加上 Traces,並且讓這所有的「監控資料」串連並關聯在一起供隨時查閱。
(補充:可觀測性已經從 1.0、2.0、發展到 3.0 甚至有人在談 4.0 了。)
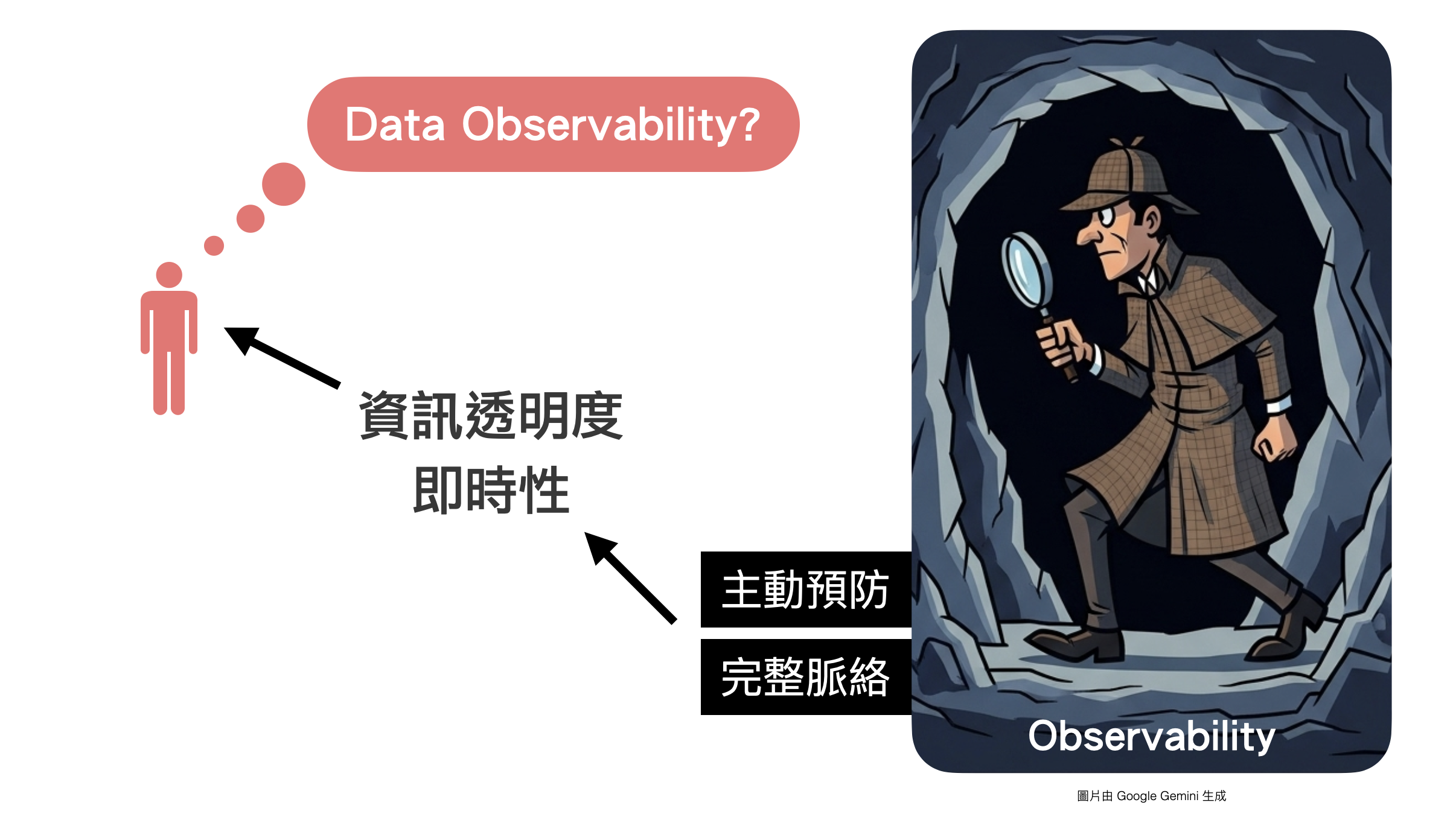
在引入了可觀測性之後,讓我們可以更有「透明度」且「即時」的瞭解系統的狀態,得以隨時觀測在哪一個時間點,系統發生了什麼事,以及該時間點下系統相互之間的影響關係。
小結
本系列文終於開始進入我們的關鍵字「可觀測性」。
如果想要了解更多關於「可觀測性」的內容,歡迎參考我在 DevOpsDays Taipei 2025 和 Marcus Tung 一起分享的演講「為什麼我們需要 Observability?」。如果你沒時間深究,也建議至少讀一下維基百科上是如何定義「可觀測性」。
本文的分享其實只有一個重點,就是點出過去「被動監控」的不足,而隨著時代、技術、思維的進步,我們需要提升「資訊透明度」與「即時性」,才能滿足「主動觀測」的需要。而當我們掌握更多的主動性,才能跳脫單點監控,以更完整脈絡的角度掌握我們的系統。
而在這樣的思維之下,我們可以思考若是將可觀測性運用至不同的領域時,分別該觀測什麼?該如何在不同領域實踐可觀測性?
IT 軟體圈有「可觀測性(Observability)」,Data 圈當然也應該要有自己的「資料可觀測性(Data Observability)」。就讓我們在後面的文章繼續認識 Data Observability 吧。
系列文連結
此系列文持續撰寫中,陸續更新連結。
