前言
大家好,我是艦長。
系列文連續鋪梗已經進入第五篇了,在上一篇我們比較了軟體圈與 Data 圈在看待 Data 時的根本差異,這一篇我們繼續聊 Data,用一個經典的比喻,來跟大家聊聊:為什麼想要取得高品質的 Data,是一件如此困難的事情?
如何取得一杯乾淨的水
在 Data 圈,為了說明資料品質,有一個常見的比喻——「如何取得一杯乾淨的水」。
想像一下,如果我想要實現水龍頭一打開就能取得一杯可以直接生飲的水,我該怎麼做才好?
(謎之音:那就先裝一台 XX 牌高級濾水器不就好了 XD)
我知道一定有人會吐嘲說還不簡單,就裝一台濾水器不就好了,只要錢夠多,你要裝多高級的濾水器都行。誒,你這樣說也沒有錯啦,但這樣我這比喻故事就說不下去了 XDDDD
所以讓我修正一下問題——從水源上游開始一直到位於最下游為止,如果想要讓不同位置、不同用途的人,都可以一打開水龍頭就取得他所需的水,我們該怎麼做才好?
好了,這次多了一些條件:
- 我們需要照顧從上游、中游到下游,於不同位置取水者的需求。
- 不同的人,對於水的需求(要求)不一定相同。
(好啦,我知道如果嚴謹討論,這些條件還是不夠完善,但就先放我一馬?)
如果大家有學過自然科學,或帶小孩去參加科博館之類的活動,其實多少都概略知道現代人的自來水系統。
- 水源來自上游的集水區,例如水庫。
- 接著水會被送到淨水廠。
- 經過淨水廠處理過的水,被送入自來水公司的地下管線。
- 最後,才進入各建築物的水系統,可以一開水龍頭就取水。
- 當然,現在家家戶戶還會自己加裝濾水器,做到打開濾水器的出水口就能直接飲用。
這整趟水系統,就像是 Data 圈處理 Data 的歷程:
- 集水區:即是各式各樣的 Data Source,是我們收集、累積、儲存 Source Data 的地方。
- 淨水廠與自來水管線:則是我們各式各樣的 Data Pipeline,這些 Pipeline 不只是將 Data 從 A 搬到 B,同時就像淨水廠會有沈澱、過濾、消毒的步驟,Data 圈也會透過 Data Pipeline 對 Source Data 做資料清洗、轉換的動作,讓下游的 Data 更貼近 Data User 需要的模樣。
- 各建築物的水系統:經過處理後的 Data,依然會需要地方儲存(或暫存),甚至就像為了供應頂樓加蓋的那一戶人家有足夠的水壓,還要額外加裝加壓器,所以除了集水區的 Data infra,你也需要為了末端的 Data User 準備他們所需的 Data infra 與 Pipeline。
- 家家戶戶的濾水器:即便淨水廠已經幫我們清潔過一次自來水,但你依然不敢直接生飲對吧?因為你會懷疑水在自來水管線或自家建物水管的運輸過程中可能有受到污染;因此在 Data User 真正開始使用 Data 前,多半還要自己花費工夫再清理與轉換一次 Data,甚至要自己檢驗 Data 品質。
- 如果不是為了飲用,日常民生用途的水,我們可以接受使用水龍頭一打開的自來水;Data 也是如此,就像金融業之於錢,電商之於庫存,同樣都叫做 Data,但有些 Data 我們的要求就是比較高,要求數字一定要正確,反之在其他情境或用途,就不一定需要這麼高的標準。
透過前面的比喻,大家應該都能理解我想要表達的內容。
- 水 = Data。
- 水來自四面八方,被匯集至多個集水區 = Data 也是如此。
- 水會受到污染,會有品質問題 = Data 也是如此。
- 水在整個水系統的過程中,已經做過多次處理,但每個處理關卡的目標及標準不同 = Data 也是如此。
- 用途不同,對於水的需求及品質要求不同 = Data 也是如此。
小結
好了,故事說的差不多了,為本文做一個小結。
Data 就像水,而 Data User 實在太常遇到,以為自己手上那杯水(Data)是乾淨的,等到喝下去肚子痛了,才發現水龍頭打開的水根本是髒水,可是明明上游淨水廠打包票說從他那邊出去的水是有通過品質檢驗的啊!
一次、兩次、三次,你覺得這種事要發生幾次,你會想要在自己家裡加裝濾水器呢?而且要加裝那種附帶水質檢測功能,會用燈號或數字明確地告訴你現在水質的濾水器。所以同樣的,你覺得 Data 要被污染幾次,Data User 才會受不了呢?
在 Data 圈一直有一句大家一定聽過的話:「Garbage In, Garbage Out」。還記得本系列文 3 提到的營運部門主管嗎?如果他拿到的是 Garbage Data,當然 BI Dashboard 只會產出 Garbage Report,於是他就等著被大老闆叮得滿頭包。
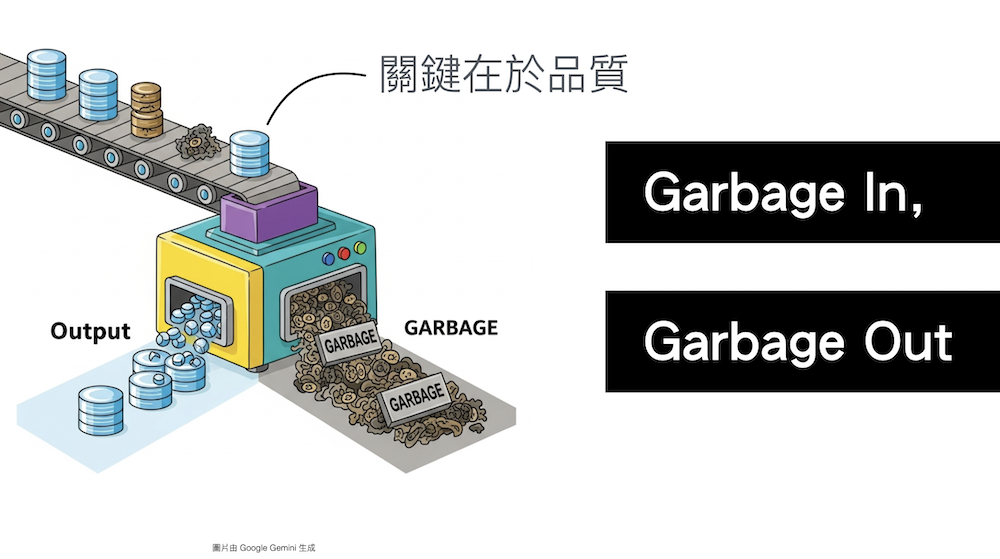
Data 很重要,Data 的品質很重要,但要如何適切的讓不同 Data User 拿到他們各自想要且品質足夠的 Data,則有許多的難度。
本文到此,我們下一篇文章見!
系列文連結
此系列文持續撰寫中,陸續更新連結。
