前言
感謝 iThome 再次邀請,由於自己從 2023 年末有較多機會接觸 MLOps 的議題,同時也注意到 GitLab 默默地有在開發 MLOps 相關功能,因此就決定這次在 iThome Cloud Summit 2024 要分享 MLOps 的內容。
其實我本來的如意算盤是想著,等到 7 月 Cloud Summit 舉辦時,GitLab 差不多也已經正式推出新功能 Model Registry,這樣時間剛好,我就能用新功能來規劃一個簡單的 Lab。
但誰知道原廠遲遲未能正式釋出 Model Registry,在 6 月底最新 Release 的 17.1 版,Model Registry 依然處於 beta 狀態,因此最後只能放棄原本的計畫了。
Lab 內容規劃
本次的 Lab 內容一如往常,前半場會是簡短的演講,先向學員分享一些基礎知識,讓學員後續在操作 Lab 時,能更理解我想要傳達的內容。
簡單解說一下,整個 Lab 的設計思路:
- 採用 GitLab 原廠的 Example Code 與流程為基底,但稍微調整內容順序,組合出我希望能讓學員體驗的內容。
- Lab 預計要讓學員體驗以下內容:
- 訓練 Model 需要 Data,所以在訓練之前,你應該會有別的 Data Pipeline 吧?因此會讓學員在 GitLab 上建立一個很簡單的 Data Pipeline,然後將 Data 存放在 Job Artifacts 中。
- 建立一個 ML Project,並且從 Data Pipeline 取得清理乾淨的 Data,接著訓練 Model,最後查看儲存在 Model experiments 的成果。
- 建立第二個 ML Project,但在訓練 Model 之前,要先 build container image,為後續訓練 Model 建立一個可用的環境。
- 有了環境之後,接著訓練 Model,一樣可以在 Model experiments 查看成果。
- 設定排程 Pipeline 定期評估 Model。
- 如果時間足夠,可以讓學員試著手動下載訓練好的 Model,然後手動上傳到 Model registry 功能。
- 透過上面的內容規劃,希望學員能注意到 MLOps 流程中需要關心幾件事:
- 訓練 Model 是需要有 Data 的,那是否應該要關心一下 Data Pipeline 的規劃,以及準備好的 Data 該如何讓下游的資料科學家可以方便的取用。
- 訓練 Model 也是需要有一個「環境」,這個環境當然也可以做成 Container,那一樣會有環境的相依性、版本、管理及維護的議題。
- 開發(訓練) Model 與開發軟體,是很不一樣的流程,你不能直接拿軟體開發流程的經驗,硬是套用到 Model 訓練的世界。對於迭代及交付頻率的要求不同,需要管理的產出物、Report 也不同。單就功能面來舉例,最少你也需要準備一個可以方便記錄 Experiments 的功能,而且這些功能如果不夠簡單方便好用,資料科學家可是不會想用的。
Lab 操作步驟
如果你這次沒來現場參加 Lab,又或者你是有來現場,但沒能做完 Lab 的學員,那我已經將操作步驟改編成可以在 gitlab.com 上執行,歡迎你嘗試看看。 (這裡也再次跟當天有在現場的學員致歉,沒想到我自己掏腰包準備的主機規格還是不夠力,所以當天 Lab 做起來的反應有點慢,甚至一度吐出 502,真是抱歉!)
注意:以下內容是在 GitLab 17.1 的環境下規劃的,如果 GitLab 版本更新,可能就會出現與下述內容不吻合的狀況!
本次 Lab 會用到的三個 Example Project,我都放在同一個 GitLab Group 中了。
事前準備
- 請先登入 GitLab.com。(如果你還沒有帳號,可以免費註冊一個。)
建立第一個 ML Project
Create new project
- 選擇
Import project - 選擇
Repository by URL - Git repository URL 輸入
https://gitlab.com/ithome-cloud-summit-2024-gitlab-mlops-lab/model_experiment_example.git
- 選擇
在剛才建立好的 GitLab Project 中新增 Project access token
- 進入
Settings > Access Tokens
- 點擊
Add new token - 設定 Token 的權限
- Select a role 設定為
Developer - Select scopes 勾選
api - 按下
create project access token - 先把得到的 Token 複製下來保存,等一下會用到。
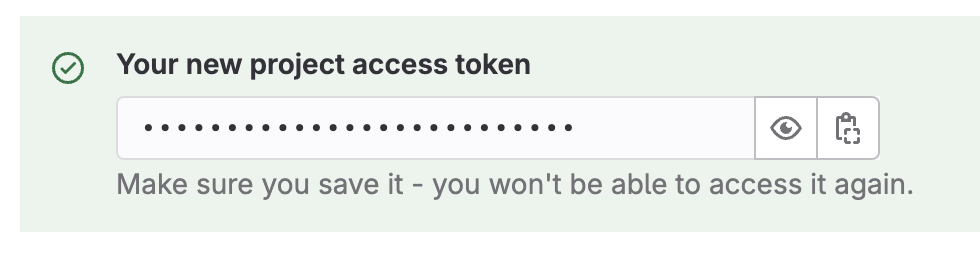 Token 應該會類似
Token 應該會類似 glpat-xxxxxXXxxxXxXxXxxXxx
- Select a role 設定為
- 進入
查一下你的 Project ID,後面會用到
- 回到你 Project 的入口頁,在右上角的「⋯」可以複製 Project ID,等一下會用到。

- 回到你 Project 的入口頁,在右上角的「⋯」可以複製 Project ID,等一下會用到。
新增 CI/CD Variables
進入
Settings > CI/CD
找到
Variables
準備新增 Variable
新增下列 2 個 Variables,在這個範例中,他們會使用到 MLFlow client 來將實驗結果上傳到 GitLab 的 Model experiments 功能。
- Key =
MLFLOW_TRACKING_URI- Visibility =
Visible - Flags 取消勾選
Protect variable - Value =
https://gitlab.com/api/v4/projects/<project_id>/ml/mlflow(記得取代為你的 Project ID)
- Visibility =
- Key =
MLFLOW_TRACKING_TOKEN- Visibility =
Masked - Flags 取消勾選
Protect variable - Value =
前面準備好的 Project access token
- Visibility =
- Key =
進入
Build > Pipeline editor,準備來新增 CI Pipeline。
點擊
Configure pipeline
移除 GitLab 自己預設幫你產生的
.gitlab-ci.ymlexample code 內容。改輸入以下內容
stages: - create image: python:3.9 create-candidates: stage: create tags: - gitlab-org-docker rules: - when: manual script: - echo $MLFLOW_TRACKING_URI - pip3 install -r requirements.txt - python3 train.py
進入
Build > Pipelines,準備手動執行 CI Pipeline。會看到類似下圖的狀況,Pipeline 呈現
Blocked的狀態。
按下右側的「箭頭」按鈕,手動執行 jobs。

正常來說,Job 會 failed。

到這裡,我們先告一個段落,先來解決「欠缺 Data」的問題;等一下再回來這個 Project。
建立 Data Pipeline Project
Create new project
- 選擇
Import project - 選擇
Repository by URL - Git repository URL 輸入
https://gitlab.com/ithome-cloud-summit-2024-gitlab-mlops-lab/example-data-wine-quality.git
- 選擇
新增
.gitlab-ci.yml建立 Data Pipeline 做簡單的資料清洗。進入
Build > Pipeline editor,準備來新增 CI Pipeline。點擊
Configure pipeline移除 GitLab 自己預設幫你產生的
.gitlab-ci.ymlexample code 內容。改輸入以下內容
stages: - data image: python:3.9 remove-blank-lines: stage: data tags: - gitlab-org-docker script: - sed '/\r/d' wine-quality-not-good.csv > wine-quality.csv - tail -n 10 wine-quality.csv artifacts: paths: - "./wine-quality.csv"
確認 Pipeline 有正常執行,並且有順利上傳 Artifacts。
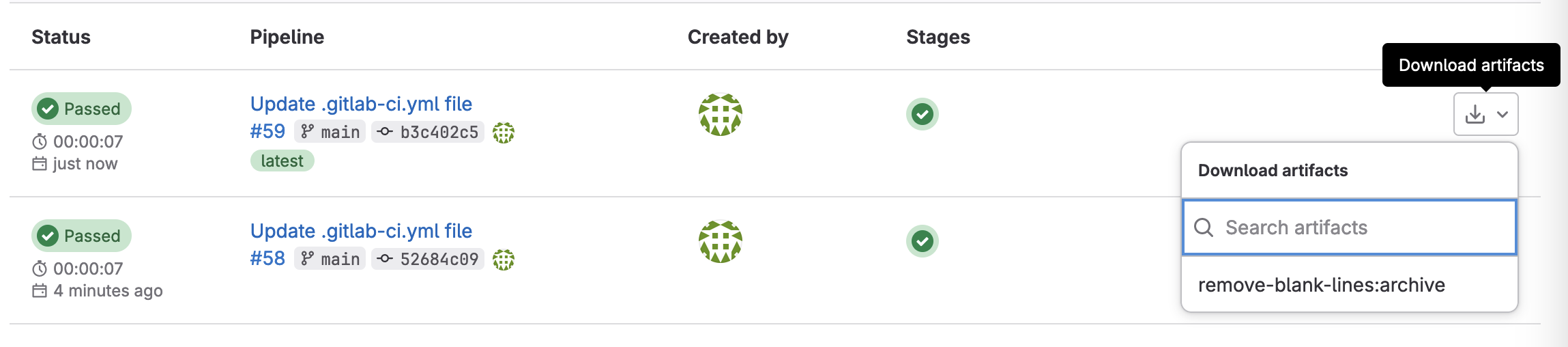
記錄一下這個 Data Pipeline 的 Project ID,下一個階段會用到。
修復第一個 ML Project
先產生一個 User 的 Personal Access Token
點擊 UI 左上角的個人 icon,進入
Preferences
再從 User settings 中找到
Access Tokens
接著 Add new token,在設置 Token 的 Select scopes 時,請勾選
api
複製並保管好你的 Token,下面會用到!
回到第一個 ML Project,並且再次進入
Build > Pipeline editor,準備修改.gitlab-ci.yml。增加更多內容
# 增加變數 variables: your_access_token: 填你的 Personal Access Token your_data_pipeline_project_id: 填你的 Data Project 的 Project ID your_data_pipeline_branch: main stages: - create image: python:3.9 create-candidates: stage: create tags: - gitlab-org-docker rules: - when: manual script: ## 透過 GitLab API 去取得其他 Project 的 Artifacts ## 複製下面這一行時,很容易遇到 空白變成 Tab 導致 yaml 格式錯誤的問題 - 'curl --location --header "PRIVATE-TOKEN: $your_access_token" --output wine-quality.csv "https://gitlab.com/api/v4/projects/$your_data_pipeline_project_id/jobs/artifacts/$your_data_pipeline_branch/raw/wine-quality.csv?job=remove-blank-lines"' ## 確認一下是否有順利取得 wine-quality.csv - ls wine-quality.csv ## 將內容印出來確認一下 - tail -n 10 wine-quality.csv - echo $MLFLOW_TRACKING_URI - pip3 install -r requirements.txt - python3 train.py再次進入
Build > Pipelines,再次手動執行 CI Pipeline。- 正常來說,這一次 Job 會成功綠燈。
- 前往
Analyze > Model experiments查看我們的成果!
建立第二個 ML Project
Create new project
- 選擇
Import project - 選擇
Repository by URL - Git repository URL 輸入
https://gitlab.com/ithome-cloud-summit-2024-gitlab-mlops-lab/data-science-ci-example.git
- 選擇
在剛才建立好的 GitLab Project 中新增 Project access token
- 進入
Settings > Access Tokens - 點擊
Add new token - 設定 Token 的權限
- Select a role 設定為
Developer - Select scopes 勾選
api - 按下
create project access token - 先把得到的 Token 複製下來保存,等一下會用到。
- Select a role 設定為
- 進入
查一下你的 Project ID,後面會用到
- 回到你 Project 的入口頁,在右上角的「⋯」可以複製 Project ID,等一下會用到。
新增 CI/CD Variables
- 進入
Settings > CI/CD - 找到
Variables,準備新增 Variable - 新增下列四個 Variable,一樣有些是給 MLFlow client 使用,有些則是給
cml-send-comment使用。- Key =
API_ENDPOINT- Visibility =
Masked - Flags 取消勾選
Protect variable - Value =
https://gitlab.com/api/v4/projects/<project_id>(記得取代為你的 Project ID)
- Visibility =
- Key =
MLFLOW_TRACKING_URI- Visibility =
Masked - Flags 取消勾選
Protect variable - Value =
https://gitlab.com/api/v4/projects/<project_id>/ml/mlflow(記得取代為你的 Project ID)
- Visibility =
- Key =
MLFLOW_TRACKING_TOKEN- Visibility =
Masked - Flags 取消勾選
Protect variable - Value =
前面準備好的 Project access token
- Visibility =
- Key =
REPO_TOKEN- Visibility =
Masked - Flags 取消勾選
Protect variable - Value =
前面準備好的 Project access token
- Visibility =
- Key =
- 進入
建立新 Branch
建立一個 Merge request
設定從新開的 branch 合併至 main branch
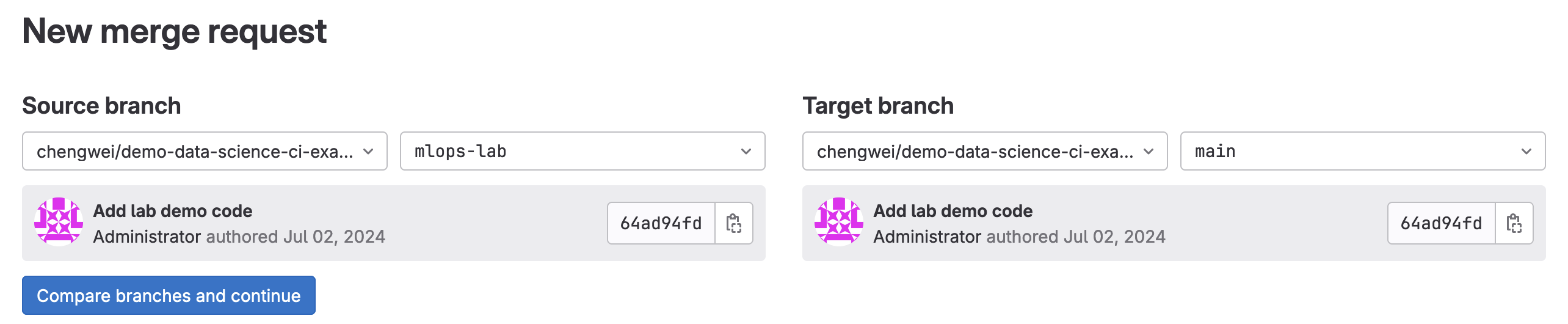
新開的 MR,應該會是 Draft 狀態
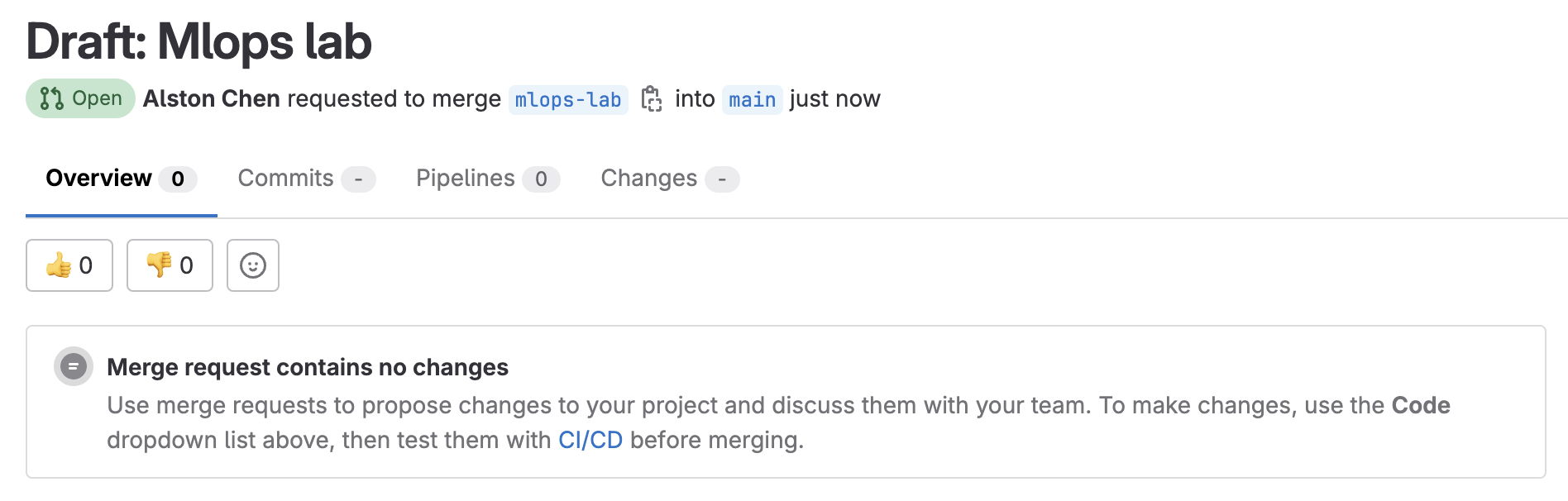
在新開的 branch 修改 Project 內容
進入 GitLab 的 Web IDE

注意 Web IDE 目前開啟的是哪一個 Branch 的 Code,請選擇剛才新增的 Branch。
修改以下檔案,觸發 pipeline。
修改
.gitlab-ci.yml修改所有的
tags:,將它改成正確的 Shared runner。# 舉例 train-commit-activated: stage: train image: "$CONTAINER_IMAGE" tags: - docker修改後結果
train-commit-activated: stage: train image: "$CONTAINER_IMAGE" tags: - gitlab-org-docker點擊左側選單送出 commit,請注意 commit message 一定要寫
train notebooks/training_example.ipynb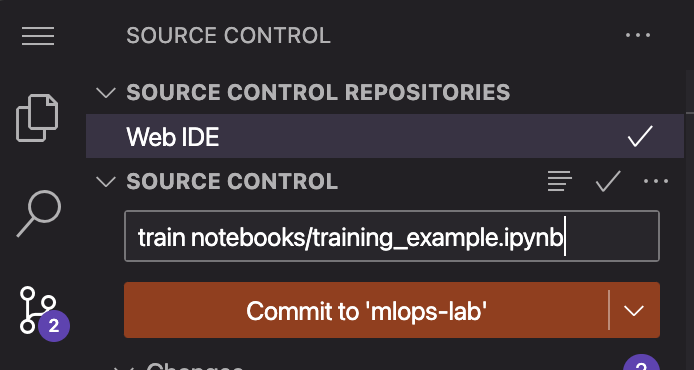
正常來說,你回到 MR 頁面,會看到 Merge request pipeline 正在 running。但老樣子,會 failed。
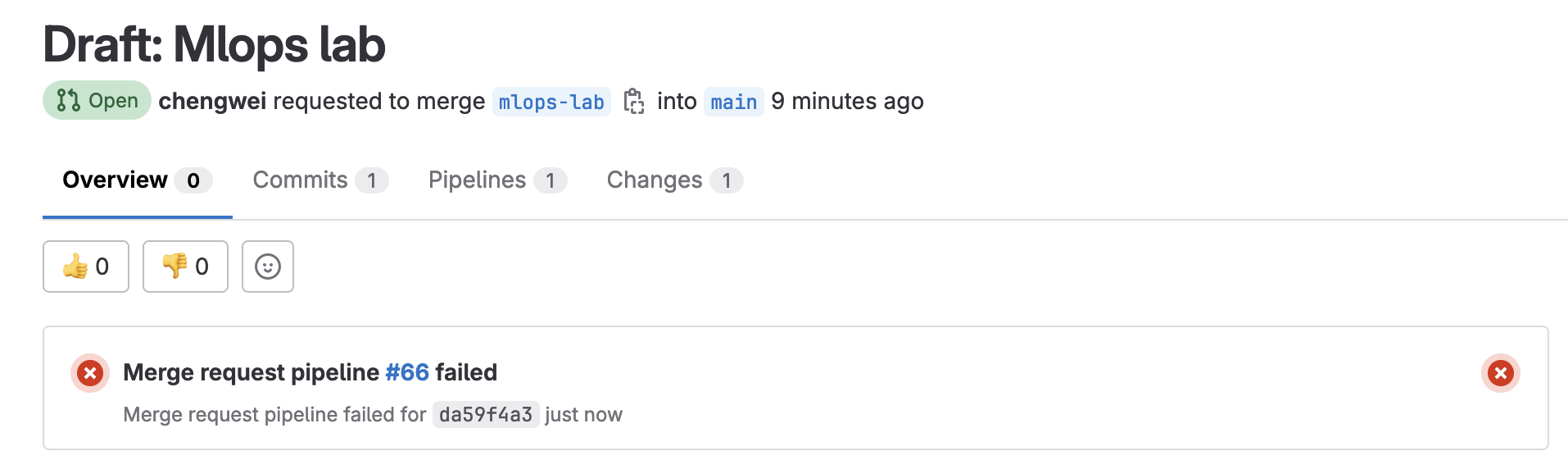
前面的 failed 是因為缺少所需的 docker image,所以要繼續修改檔案內容,先增加 build image 的任務
先修改
.gitlab-ci.yml新增更多內容,如下述
# 增加一個 stage stages: - build - train - score # 增加一個 job,用來 build image build-ds-image: tags: - gitlab-org-docker stage: build services: - docker:20.10.16-dind image: name: docker:20.10.16 script: - docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY - docker build -t $CONTAINER_IMAGE . - docker push $CONTAINER_IMAGE rules: - if: $CI_PIPELINE_SOURCE == "merge_request_event" && $CI_MERGE_REQUEST_TARGET_BRANCH_NAME == $CI_DEFAULT_BRANCH changes: - Dockerfile - requirements.txt allow_failure: false修改
Dockerfile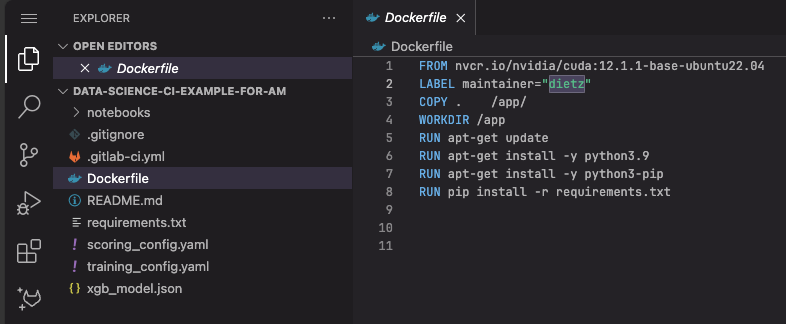
修改
LABEL maintainer="dietz"改成自己的名字LABEL maintainer="YOUR NAME"再次送出 commit,請注意 commit message 一定要寫
train notebooks/training_example.ipynb這次 Pipeline 就會正常執行
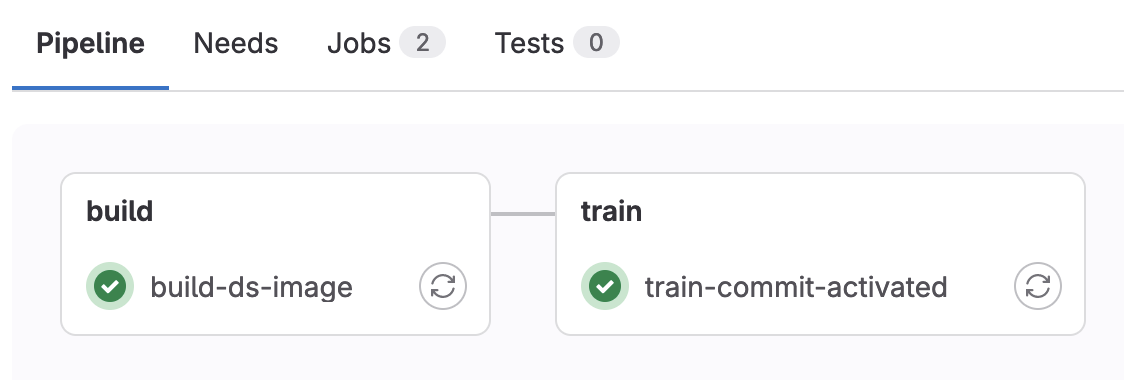
前往
Analyze > Model experiments,即可查看本次 ML 訓練的實驗紀錄。
新增另外 1 個 Job
publish-metrics-comment繼續修改
.gitlab-ci.yml新增以下內容# 在 stages: 多增加一個 notify stages: - build - train - score - notify # 在增加一個 Job publish-metrics-comment: stage: notify image: dvcorg/cml-py3:latest tags: - gitlab-org-docker script: - cml-send-comment model_metrics.md --repo $CI_PROJECT_URL rules: - if: "$CI_COMMIT_MESSAGE =~ /\\w+\\.ipynb/" when: on_success allow_failure: true為了避免 pipeline 重複 build image,先把 Dockerfile 改回來
把上一個 Commit 修改的
LABEL maintainer="YOUR NAME"改回原本的模樣LABEL maintainer="dietz"再次送出 commit,請注意 commit message 一定要寫
train notebooks/training_example.ipynb再次等待 Pipeline 執行,這次會少了 build image,多一個 Stage: notify。
等待 Pipeline 跑完,就可以回到 Merge request,你會發現在 MR 的 Comment 中,也會出現實驗成果。
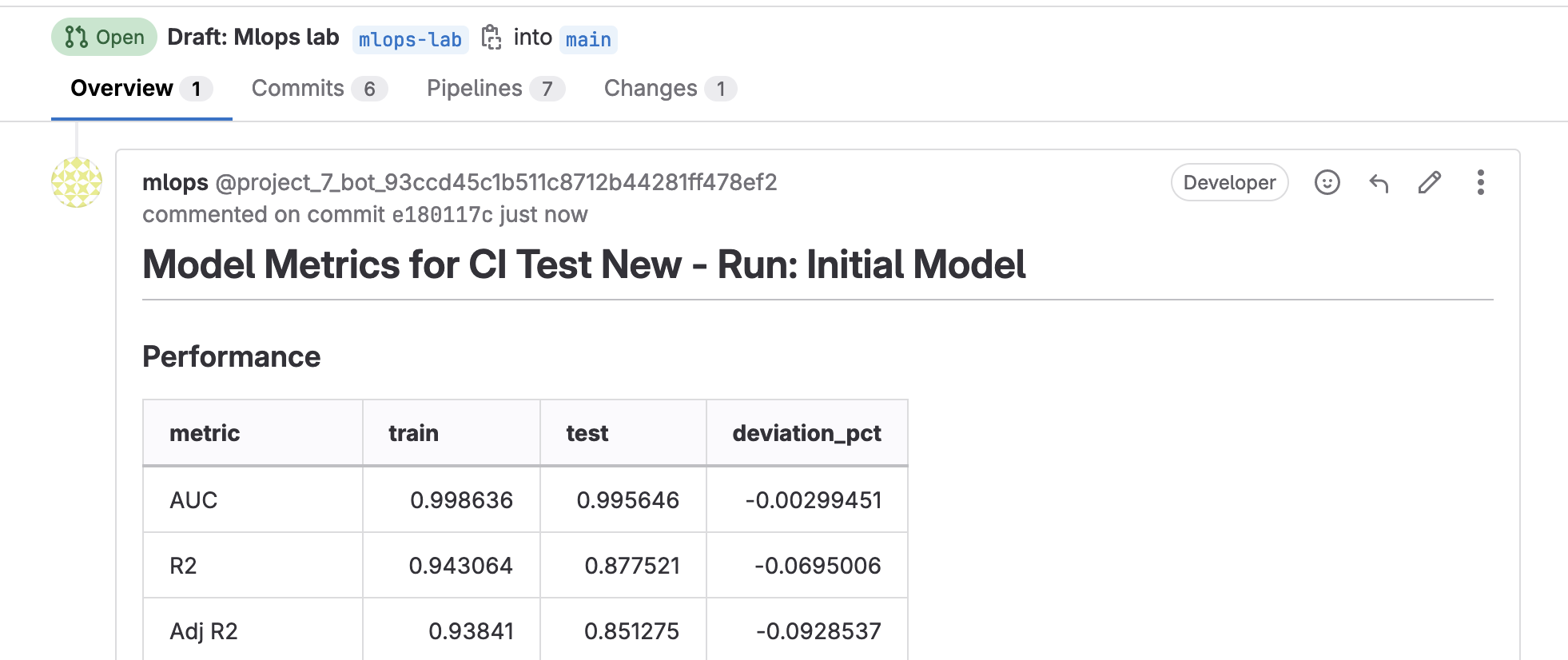
讓我們觸發另一種 pipeline。
繼續修改
.gitlab-ci.yml,增加以下內容write-to-wiki: stage: notify image: dvcorg/cml-py3:latest needs: - score-scheduled script: - metrics=$(echo $CI_PIPELINE_URL ; cat model_metrics.md) - curl --request POST --data-urlencode "format=markdown" --data-urlencode "title=$CI_JOB_STARTED_AT" --data-urlencode "content=$metrics" --header "PRIVATE-TOKEN:$REPO_TOKEN" "$API_ENDPOINT/wikis" rules: - if: $CI_PIPELINE_SOURCE == "schedule" allow_failure: true送出 commit,請注意這次 commit message 不一樣了,請一定要寫
score notebooks/scoring_example.ipynb等待 Pipeline 執行,這次會有另外 2 個 Job
一樣可以在 MR 的 Comment 看到成果
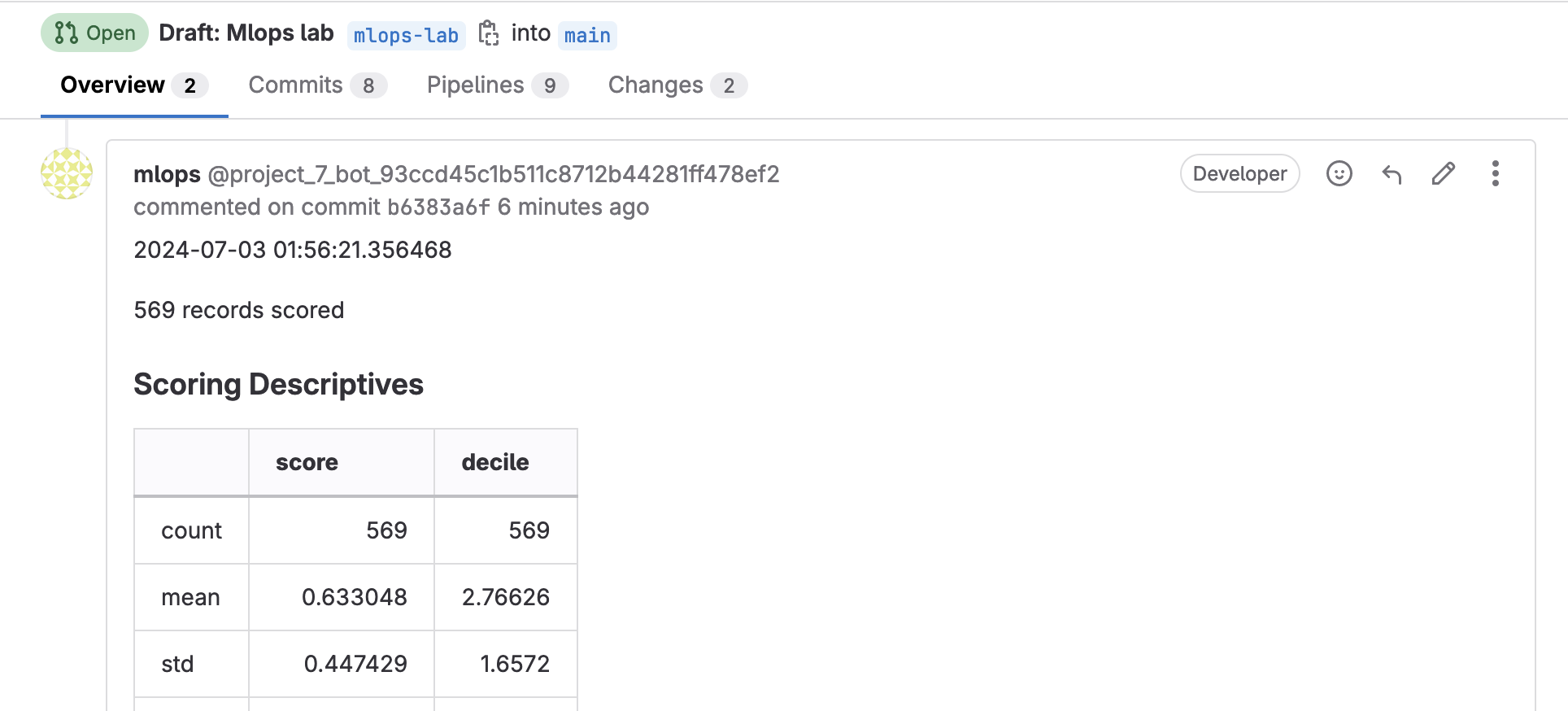
建立定期執行的 Pipeline
前往
Build > Pipeline schedules
建立一個定期執行的 pipeline

在建立時,其中有幾個要特別填寫
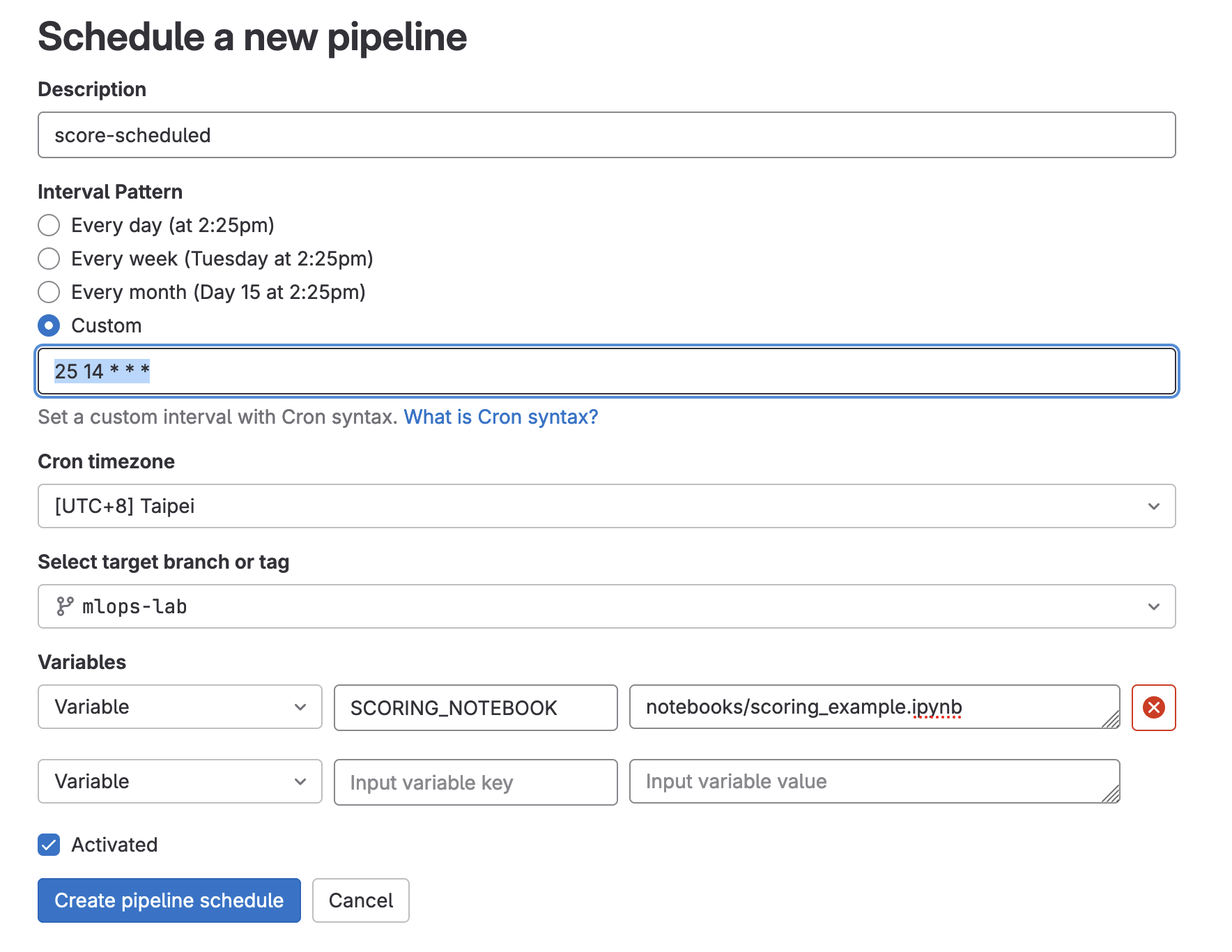
Interval Pattern
先選擇
Custom接著請自己看一下現在的時間,填一個 3-5 分鐘後的時間。
舉例:如果現在是 14:15,那就填一個 3 分鐘後會觸發的的時間
18 14 * * *(
分 時 * * *)Cron timezone
請選擇
[UTC+8] TaipeiSelect target branch or tag
請選擇我們一直在改來改去的那一個 Branch
Variables
新增一個 Variable
SCORING_NOTEBOOK,值請填寫notebooks/scoring_example.ipynb
接著就等時間到,等待 Pipeline 排程自動觸發。
或者是自己按「箭頭」手動觸發!

同樣等待 Pipeline 執行完畢
前往
Plan > wiki去查看成果
在右側的選單,可以看到多了一個 Page
點進去後,一樣可以看到 Scoring 的成果。
手動上傳 Model 到 Model registry
進入
Deploy > Model registry。
手動填寫資料,並且將 Model 上傳。
小結
如果你按著上面的操作步驟完成了 Lab,我想你應該可以體會到整個 Lab 的設計真的是「輕輕鬆鬆」或者應該說只是「小試身手」;就如同我前面解釋 Lab 設計思路的說明,Lab 規劃的體驗目標是點出那些「ML 開發」與「軟體開發」流程的差異。
訓練 Model 需要 Data,如果你想要訓練 Model 還是要提醒一下,你家有礦(Data)嗎?沒有礦那要拿什麼來訓練?另外你有能力辨識金礦?以及搭建良好的挖礦流程(Data Pipeline)嗎?
另外,Model 的迭代頻率、交付頻率又是如何?適合跟軟體開發的迭代與交付頻率類比嗎?在那樣的頻率之下,你的團隊真的需要一個「很高效率」的 MLOps 流程或平台嗎?
你們在訓練的 Model 是哪一種?你是從零開始訓練一個新一代的 LLM 這種等級的 Model?還是只是拿前人已經訓練好的 Model 做再訓練呢?不同的訓練情境,可以使用相同的 MLOps 流程與平台嗎?
最後,所以你搭建的 MLOps 流程與平台到底是要服務哪些「使用者」?還是其實你需要的是更新興的其他 XXXOps,例如:PromptOps、RAGOps、LLMOps?
最後的最後,再做一些小提醒,前面 Lab 的內容,在 Pipeline 的規劃本身也有很多延伸議題是需要注意的,如果你真的打算參考 Lab 建立一個正式的 Pipeline,請務必多思考幾件事:
- Access Token 的管理與取用,以及每一個 Job 到底需要多少的權限?
- Data Pipeline、Build image、Train Model 三種 Pipeline 是可以拆開來處理的,Lab 規劃的流程一定無法直接適用在你的團隊與情境中,請找你的資料科學家們討論,到底怎麼樣的流程才是真正適合他們的
- Image 的 Size,其實那些 Package 裝一裝 build 出來的 image 還滿肥大的
- 另外就是在 Stage: notify 中,使用的 image
dvcorg/cml-py3,雖然它能很簡單以一行指令cml-send-comment model_metrics.md就幫你把實驗結果發佈在 MR 的 Comment 中,但這個 image 也超肥的
總之,不管是哪種 XXXOps,找到適合你的流程、工具,並且在整合過程又照顧到各種面向,絕對不是一件簡單的事,只能說一句大家加油嘍~
